| |
|
|
Lead-Finder combines extra precise protein-ligand docking and binding energy estimation with
a high speed of calculations providing efficient solutions for the following tasks:
- Protein structure preparation (cleaning)
Lead-Finder automatically prepares fully functional protein structures
(for docking and other molecular modeling purposes) starting from crude heavy
atom coordinates (usually present in PDB files and homology models) by adding
hydrogen atoms to protein residues (ligands, substrates, cofactors) at a given
pH. Original electrostatic model is implemented in Lead-Finder for accurate
calculations of ionization properties of proteins, which was validated in predicting
100 diverse pKa values of ionizable protein residues.
- Ligand docking
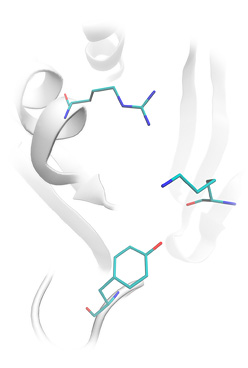
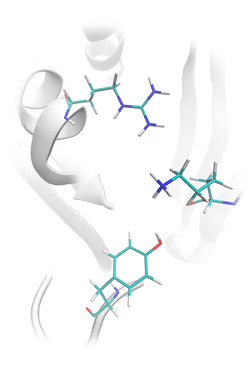
Lead-Finder correctly predicts the structure of non-covalent and covalently bound
protein-ligand complexes. Accuracy of protein-ligand docking was validated on the set
of 407 protein-ligand complexes, which is currently the most extensive
benchmarking study of such kind. Our test set was composed of test sets of such
docking programs as
FlexX,
Glide SP, Glide XP,
Gold,
LigandFit,
MolDock,
Surflex
which allowed straightforward comparison of Lead-Finder and original results for the
competitive programs. As can be seen from our benchmarking studies, Lead-Finder
outperformed all competitive programs on their native test sets.
- Virtual screening
Lead-Finder can screen massive libraries of chemical compounds against a protein target
to find potent binders with high fidelity at a high speed of calculations
(~5000 compounds per processor/core per day). Ability of Lead-Finder to find active
compounds in mixtures with inactive was extensively validated on the set
of 34 therapeutically relevant protein targets, showing impressive enrichment results
in almost all cases.
- Binding energy estimations
Lead-Finder performs extra precise estimations of the free energy of protein-ligand
binding based on an original semi-empiric molecular-mechanical scoring function.
Accuracy of binding energy estimations was validated on the set of experimentally
measured binding energies of 330 diverse protein-ligand complexes, which is currently
the most extensive benchmarking study of such kind. Root mean square deviation of Lead-Finder
predictions from experimental binding energies comprised 1.50 kcal/mol, which is the highest
accuracy compared to competitive docking programs.

| |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
